Facility location problems¶
Todo
Adapt figures, check maths Computational experiment comparing formulations Adapt kmedian — seems to be still gurobi version
To import SCIP in python, do:
from pyscipopt import Model, quicksum, multidict
We will deal here with facility location, which is a classical optimization problem for determining the sites for factories and warehouses. A typical facility location problem consists of choosing the best among potential sites, subject to constraints requiring that demands at several points must be serviced by the established facilities. The objective of the problem is to select facility sites in order to minimize costs; these typically include a part which is proportional to the sum of the distances from the demand points to the servicing facilities, in addition to costs of opening them at the chosen sites. The facilities may or may not have limited capacities for servicing, which classifies the problems into capacited and uncapacited variants. We will analyze several formulations; it is not straightforward to determine which are good and which are bad, but we will provide some tips for helping on this.
The structure of this chapter is the following. In Section Capacitated facility location problem, we consider the capacity constrained facility location problem, which will be used to explain the main points of a program in SCIP/Python for solving it. In Section Weak and strong formulations, we discuss the quality of different formulations. In Section The k-Median Problem, we will present a type of facility location problem that minimizes the sum of the distance to the nearest facility, where the number of facilities is fixed to \(k\): the \(k\)-median problem In Section The k-Center Problem, we consider a type of facility location problems where the maximum value of the distance from a customer to one of the \(k\) open facilities is to be minimized. Thus, in this problem we want to find the minimum of maximum value. This is often a tough problem, hard to tackle with a mathematical optimization solver; we will describe some workarounds.
Capacitated facility location problem¶
The capacitated facility location problem is the basis for many practical optimization problems, where the total demand that each facility may satisfy is limited. Hence, modeling such problem must take into account both demand satisfaction and capacity constraints.
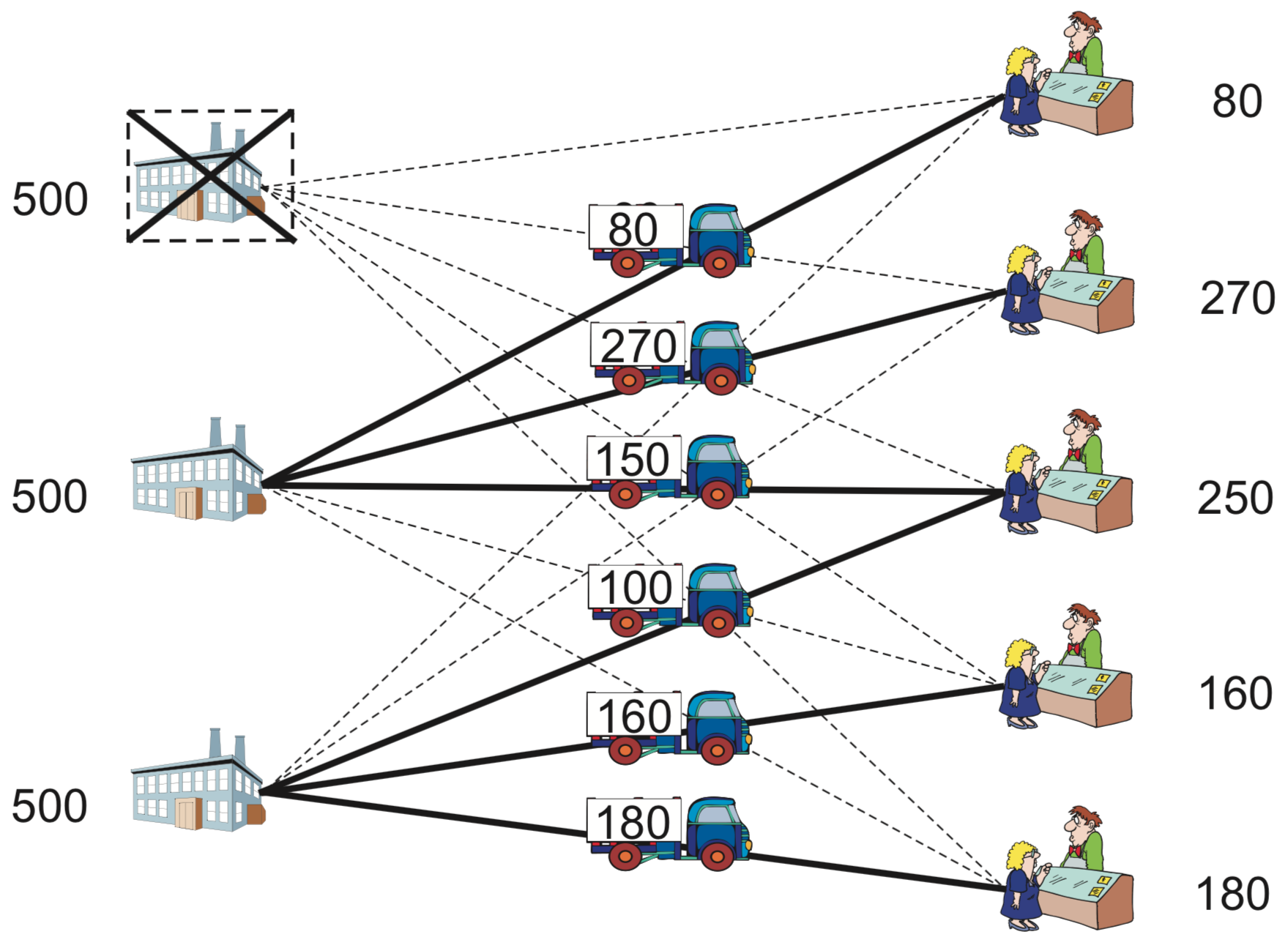
Let us start with a concrete example. Consider a company with three potential sites for installing its facilities/warehouses and five demand points, as in Section Transportation Problem. Each site \(j\) has a yearly activation cost \(f_j\), i.e., an annual leasing expense that is incurred for using it, independently of the volume it services. This volume is limited to a given maximum amount that may be handled yearly, \(M_j\). Additionally, there is a transportation cost \(c_{ij}\) per unit serviced from facility \(j\) to the demand point \(i\). These data are shown in Table Data for the facility location problem: demand, transportation costs, fixed costs, and capacities..
| Customer \(i\) | 1 | 2 | 3 | 4 | 5 | ||
|---|---|---|---|---|---|---|---|
| Annual demand \(d_i\) | 80 | 270 | 250 | 160 | 180 | ||
| Facility \(j\) | \(c_{ij}\) | \(f_j\) | \(M_j\) | ||||
| 1 | 4 | 5 | 6 | 8 | 10 | 1000 | 500 |
| 2 | 6 | 4 | 3 | 5 | 8 | 1000 | 500 |
| 3 | 9 | 7 | 4 | 3 | 4 | 1000 | 500 |
This situation and its solution are represented in Figure Facility location.
Facility location
Let us formulate the above problem as a mathematical optimization model. Consider \(n\) customers \(i = 1, 2, \ldots, n\) and \(m\) sites for facilities \(j = 1, 2, \ldots, m\). Define continuous variables \(x_{ij} \geq 0\) as the amount serviced from facility \(j\) to demand point \(i\), and binary variables \(y_j = 1\) if a facility is established at location \(j\), \(y_j = 0\) otherwise. An integer-optimization model for the capacitated facility location problem can now be specified as follows:
The objective of the problem is to minimize the sum of facility activation costs and transportation costs. The first constraints require that each customer’s demand must be satisfied. The capacity of each facility \(j\) is limited by the second constraints: if facility \(j\) is activated, its capacity restriction is observed; if it is not activated, the demand satisfied by \(j\) is zero. Third constraints provide variable upper bounds; even though they are redundant, they yield a much tighter linear programming relaxation than the equivalent, weaker formulation without them, as will be discussed in the next section.
The translation of this model to SCIP/Python is straightforward; it is done in the program that follows.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | def flp(I,J,d,M,f,c):
model = Model("flp")
x,y = {},{}
for j in J:
y[j] = model.addVar(vtype="B", name="y(%s)"%j)
for i in I:
x[i,j] = model.addVar(vtype="C", name="x(%s,%s)"%(i,j))
for i in I:
model.addCons(quicksum(x[i,j] for j in J) == d[i], "Demand(%s)"%i)
for j in M:
model.addCons(quicksum(x[i,j] for i in I) <= M[j]*y[j], "Capacity(%s)"%i)
for (i,j) in x:
model.addCons(x[i,j] <= d[i]*y[j], "Strong(%s,%s)"%(i,j))
model.setObjective(
quicksum(f[j]*y[j] for j in J) +
quicksum(c[i,j]*x[i,j] for i in I for j in J),
"minimize")
model.data = x,y
return model
|
Data for this problem may be specified in Python as follows:
1 2 3 4 5 6 7 8 | I, d = multidict({1:80, 2:270, 3:250, 4:160, 5:180})
J, M, f = multidict({1:[500,1000], 2:[500,1000], 3:[500,1000]})
c = {(1,1):4, (1,2):6, (1,3):9,
(2,1):5, (2,2):4, (2,3):7,
(3,1):6, (3,2):3, (3,3):4,
(4,1):8, (4,2):5, (4,3):3,
(5,1):10, (5,2):8, (5,3):4,
}
|
We can now solve the problem:
1 2 3 4 5 6 7 8 9 | model = flp(I, J, d, M, f, c)
model.optimize()
EPS = 1.e-6
x,y = model.__data
edges = [(i,j) for (i,j) in x if model.GetVal(x[i,j]) > EPS]
facilities = [j for j in y if model.GetVal(y[j]) > EPS]
print "Optimal value=", model.GetObjVal()
print "Facilities at nodes:", facilities
print "Edges:", edges
|
The optimal solution obtained suggests establishing the facilities at Sites 2 and 3 only, as shown in Table Optimum solution for the facility location problem example.. This solution incurs minimum total cost of 5610 for servicing all the demands.
| Customer | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| Facility | Volume transported | Status | ||||
| 1 | 0 | 0 | 0 | 0 | 0 | closed |
| 2 | 80 | 270 | 150 | 0 | 0 | open |
| 3 | 0 | 0 | 100 | 160 | 180 | open |
1 2 3 | Optimal value= 5610.0
Facilities at nodes: [2, 3]
Edges: [(1, 2), (3, 2), (3, 3), (4, 3), (2, 2), (5, 3)]
|
Weak and strong formulations¶
Let us consider the facility location problem of the previous section, in a situation where the capacity constraint is not important (any quantity may can be produced at each site). This is referred to as the uncapacitated facility location problem. One way of modeling this situation is to set the value of \(M\) in the constraint
as a very large number. Notice that the formulation is correct even if we omit constraints \(x_{ij} \leq d_j y_j, \mbox{ for } i=1,\cdots,n; j=1,\cdots,m\). Removing that constraint, the problem may suddenly become very difficult to solve, especially as its size increases; the reason is the big :math:`M` pitfall.
Parameter \(M\) represents a large enough number, usually called Big M; it is associated with one of the biggest pitfalls for beginners in mathematical optimization. The idea behind the constraint is to model the fact that “if we do not activate a warehouse, we cannot transport from there”. However, large values for \(M\) do disturb the model in practice. Constraints with a “Big M” may be a burden to the mathematical optimization solver, making the model extremely difficult to solve.
Tip
Modeling tip 2
A large number \(M\) must be set to a value as small as possible
Whenever possible, it is better not to use a large number. If its use is necessary, choose a number that is as small as possible, as long as the formulation is correct. Using large numbers, as \(M=9999999\), is unthinkable, except for very small instances.
In the uncapacitated facility location problem, a correct formulation is to set the capacity \(M\) equal to the total amount demanded. However, it is possible to improve the formulation by adding the contraints \(x_{ij} \leq d_i y_j\). The natural question here is “what formulation should we use”? Of course, the answer depends on the particular case; but in general stronger formulations are recommended. Here, the strength of a formulation is not ambiguous: it can be defined in terms of the linear optimization relaxation as follows.
Definition: Strong and Weak Formulations
Suppose that there are two formulations \(A\) and \(B\) for the same problem. By excluding the integrality constraints (which force variables to take an integer value), we obtain the linear optimization relaxation. Let the feasible region of formulations be \(P_A\) and \(P_B\). When the region \(P_B\) contains \(P_A\), i.e., \(P_A \subset P_B\), formulation \(A\) is stronger than formulation \(B\) (analogously, \(B\) is weaker than \(A\)).
Intuitively, as \(P_A\) is tighter than \(P_B\), the upper bound obtained by the relaxation in a maximization problem (or the lower bound in minimization) is closer to the optimum of the integer problem.
is stronger than using only constraints
To verify it, let \(P_A\) be the feasible region using the former constraints and \(P_B\) the feasible region when using the latter; observe that the latter constraints are obtained by adding the former, hence \(P_A \subseteq P_B\)
A truly stronger formulation is either indicated by having \(P_A \subset P_B\), or by verifying that solution of the linear optimization relaxation of \(B\) is not included in \(P_A\).
As for the question “is it always preferable to use a stronger formulation?”, there is not a theoretical answer; distinguishing each case is part of the mathematical modeling art.
Let us try to give some guidance on this. Often, stronger formulations require many more constraints or variables than weaker formulations. In the previous example, the strong formulation requires \(n m\) constraints, while the weak requires only \(n\). The time for solving the linear relaxation, which depends on the number of constraints and variables, is likely to be longer in the case of the stronger formulation. Hence, there is a trade-off between shorter times for solving linear optimization relaxations in weaker formulations, and longer computational times for branch-and-bound; indeed, the enumerating tree is likely smaller for stronger formulations. As a guideline, as the size of the enumeration tree grows very rapidly when the scale of the problem increases, stronger formulations are considered more desirable (even if the number of constraints and variables becomes larger).
The \(k\)-Median Problem¶
There are many variants of the facility location problem; here we will consider the following classic problem.
Median problem
Select a given number of facilities from possible points in a graph, in such a way that the sum of the distances from each customer to the closest facility is minimized.
Often, the number of facilities to be selected is predetermined in advance; this number is commonly denoted \(k\) (or \(p\)), and the corresponding problem is given this symbol as a suffix.
The \(k\)-median problem is hence a variant of the uncapacitated facility location problem and specifically seeks to establish \(k\) facilities, without considering fixed costs.
The distance from the customer \(i\) to facility \(j\) is denoted \(c_{ij}\), the set of customers by \(\{1,n\}\), and the set of potential places for facilities by \(\{1,m\}\). In the most common situation, it is assumed that facilities and customers share the same set of points. Let us define the following variables:
Using the symbols and variables defined above, the \(k\)-median problem can be formulated as an integer-optimization model.
However, as explained in the previous section, this constraints will lead to much worse values in the linear relaxation, and should be avoided.
The objective function minimizes the total cost of servicing all demand points.
As an illustration of this problem, consider the solution obtained for a graph with 200 vertices placed randomly in the two-dimensional unit box, represented in Figure k-median. Costs are given by the Euclidean distance between the points, and each of the vertices is a potential location for a facility.
\(k\)-median
The following Python program shows how to create a model for this problem, implemented as a function that takes the problem’s data as parameters, and returns variable objects x and y as attribute data of the model object.
The \(k\)-Center Problem¶
The \(k\)-median problem, considered above, has an interesting variant called the \(k\)-center problem.
Center problem
Select a given number of facilities from possible points in a graph, in such a way that the maximum value of a distance from a customer to the closest facility is minimized.
\(k\)-center
Essentially, the problem seeks an assignment of facilities to a subset of vertices in the graph so that each customer’s vertex is “close” to some facility. As in the \(k\)-median problem, the number of facilities to be selected is predetermined in advance, and fixed to a value \(k\). Input data for the \(k\)-center problem is also the distance \(c_{ij}\) from the customer \(i\) to facility \(j\), the set of customers by \(\{1,n\}\), and the set of potential places for facilities by \(\{1,m\}\); often, again, it is assumed that facilities and customers share the same set of points. Variables have the same meaning:
In addition, we introduce a continuous variable \(z\) to represent the distance/cost for the customer which is most distant from an established facility. Using these symbols and variables, the \(k\)-center problem can be formulated as the following mixed-integer optimization problem.
The first constraints require that each customer \(i\) is assigned to exactly one facility. The second constraints ensure that exactly \(k\) facilities are opened. The third constraints force facility \(j\) to be activated some customer \(i\) is assigned to \(j\). The fourth constraints determine \(z\) to take on at least the value weight \(c_{ij}\), for all facilities \(j\) and customers \(i\) assigned to \(j\). A version of these constraints which may be more natural, but which is much weaker, is to specify instead \(c_{ij} x_{ij} \leq z, \mbox{ for } i=1,\cdots,n; j=1,\cdots,m\). Intuitively, we can reason that in the strong formulation, as we are adding more terms in the left-hand side, the corresponding feasible region is tighter. The objective function represents the distance that the customer which is served by the most distant facility, as calculated by the third constraints, must travel.
The objective of the \(k\)-center problem is a classic case of minimizing a maximum value, also called a min-max objective; this is a type of problems for which mathematical optimization solvers are typically weak.
The following Python program shows how to create a model for the \(k\)-center problem; it is very similar to the program used to solve the \(k\)-median problem.
Note
Margin seminar 4
Techniques in linear optimization
As illustrated in the text, the problem of “minimization of the maximum value” can be reduced to a standard linear optimization, by adding a new variable and a few modifications to the model. Here, we will describe with more detail these techniques in linear optimization. Let us give a simple example. Assume that we want to minimize the maximum of two linear expressions, \(3x_1 + 4x_2\) and \(2x_1 + 7x_2\). For this, we introduce a new variable \(z\) and the constraints:
With the addition of these linear constraints, minimizing \(z\) will correctly model the minimization of the maximum of those two expressions.
A related topic that often arises in practice is the minimization of the absolute value \(| x |\) of a real variable \(x\) , which is a nonlinear expression. We can linearize it by means of two non-negative variables \(y\) and \(z\). Firstly, we compute the value of \(x\) in terms of \(y\) and \(z\), though the constraint \(x = y - z\). Now, since \(y \geq 0\) and \(z \geq 0\), we can represent a positive \(x\) with \(z=0\) and \(y>0\), and a negative \(x\) with \(y=0\) and \(z>0\). Then, \(|x|\) can be written as \(x+y\). In other words, all occurrences of \(x\) in the formulation are replaced by \(y-z\), and \(|x|\) in the objective function is replaced by \(y+z\).
It is also possible to handle an absolute value by simply adding one variable \(z\) and then imposing \(z \geq x\) and \(z \geq -x\). When minimizing \(z\), if \(x\) is non-negative, then the contraint \(z \geq x\) is active; otherwise, \(z \geq -x\) is binding. Variable \(z\) replaces \(|x|\) in the objective function.
Tip
Modeling tip 3
An objective function that minimizes a maximum value should be avoided, if possible.
When an integer optimization problem is being solved by the branch-and-bound method, if the objective function minimizes the maximum value of a set of variables (or maximizes their minimum value), there is a tendency to have large values for the difference between the lower bound and the upper bound (the so-called duality gap). In this situation, either the time for solving the problem becomes very large, or, if branch-and-bound is interrupted, the solution obtained (the incumbent solution) is rather poor. Therefore, when modeling real problems, it is preferable to avoid such formulations, if possible.
The \(k\)-Cover Problem¶
The \(k\)-center problem, considered above, has an interesting variant which allows us to avoid the min-max objective, based on the so-called the \(k\)-cover problem. In the following, we utilize the structure of \(k\)-center in a process for solving it making use of binary search.
Consider the graph \(G_{\theta}=(V,E_{\theta})\) consisting of the set of edges whose distances from a customer to a facility which do not exceed a threshold value \(\theta\), i.e., edges \(E_{\theta} = \{\{i,j\} \in E : c_{ij} \leq \theta\}\). Given a subset \(S \subseteq V\) of the vertex set, \(S\) is called a cover if every vertex \(i \in V\) is adjacent to at least one of the vertices in \(S\). We will use the fact that the optimum value of the \(k\)-center problem is less than or equal to \(\theta\) if there exists a cover with cardinality \(|S|=k\) on graph \(G_{\theta}\).
Define \(y_j = 1\) if a facility is opened at \(j\) (meaning that the vertex \(j\) is in the subset \(S\)), and \(y_j = 0\) otherwise. Furthermore, we introduce another variable:
Let us denote by \([a_{ij}]\) the incidence matrix of \(G_{\theta}\), whose element \(a_{ij}\) is equal to \(1\) if vertices \(i\) and \(j\) are adjacent, and is equal to \(0\) otherwise. Now we need to determine whether the graph \(G_{\theta}\) has a cover \(|S|=k\); we can do that by solving the following integer-optimization model, called the \(k\)-cover problem on \(G_{\theta}\):
Notice that the adjacency matrix is built upon a given value of distance \(\theta\), based on which is computed the set of facilities that may service each of the customers within that distance. For a given value of \(\theta\) there are two possibilities: either the optimal objective value of the previous optimization problem is zero (meaning that \(k\) facilities were indeed enough for covering all the customers withing distance \(\theta\)), of it may be greater that zero (meaning that there is at least one \(z_i>0\), and thus a customer could not be serviced from any of the \(k\) open facilities). In the former case, we attempt to reduce \(\theta\), and check if all customers remain covered; in the latter, \(\theta\) is increased. This process is repeated until the bounds for \(\theta\) are close enough, in a process called binary search.

Binary search method for solving the \(k\)-center problem.
An illustration is provided in Figure Search for optimum \theta with binary search..
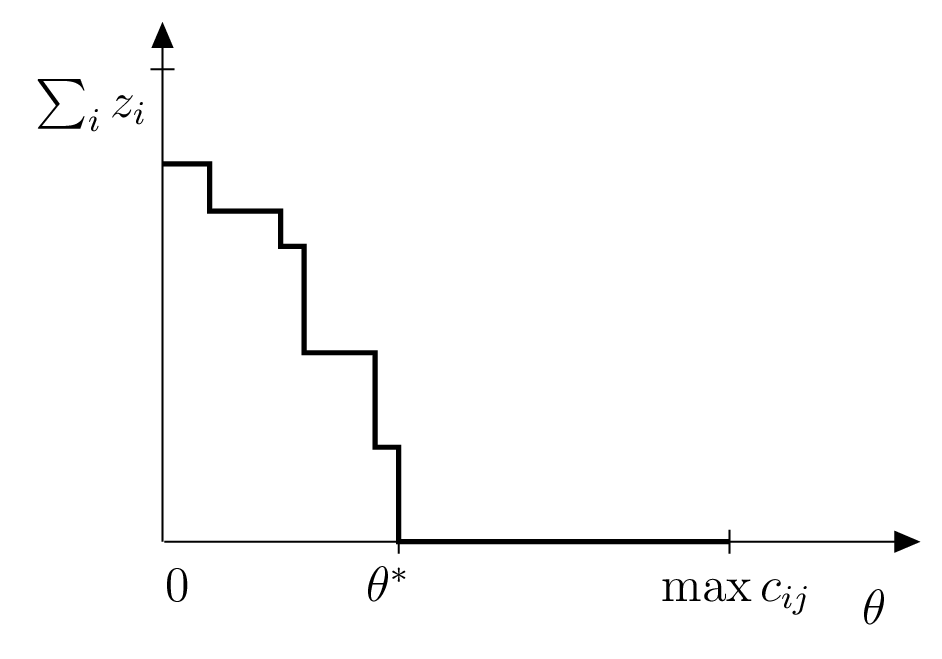
Search for optimum \(\theta\) with binary search.
Using these ideas, we can get the optimal value of the \(k\)-center problem by the following binary search method.
In Table Solution and runtimes for a random instance. we provide some numbers, for having just an idea of the order of magnitude of the computational times involved in these problems. They concern an instance with 200 vertices randomly distributed in the plane and \(k=5\).
| max distance | CPU time (s) | |
|---|---|---|
| \(k\)-median | 0.3854 | 3.5 |
| \(k\)-center | 0.3062 | 645.5 |
| \(k\)-cover + binary search | 0.3062 | 2.5 |
As we can see, \(k\)-cover within binary search method allows the computation of the \(k\)-center solution in a time comparable to that required for the \(k\)-median solution.
From a practical point of view, the \(k\)-center solution is usually preferable to that of \(k\)-median. Indeed, the longest time required for servicing a customer is frequently an important criterion to be considered by a company, and this may be prohibitively large on the \(k\)-median solution.